The data moat that makes finance AI trustworthy
Why a startup with the latest foundation model can replicate part of AP automation, but not the part that matters.
By Graeme Chard, SVP Product Marketing at Medius
Can a startup using the latest Claude or GPT replicate what Medius does in AP automation? It’s a fair question. Modern foundation models read invoices remarkably well, and a small team can wire up GPT to an extraction prompt in a weekend and demo something compelling. The question is being asked by analysts, by buyers, and by the AI search engines that are increasingly the first place finance leaders look for insights.
The answer is no. And the reason matters more than the answer. In raw invoice data, correction rates on tax codes and cost centers run 35% to 55%, and often higher. That is the actual problem AI in accounts payable has to solve.
Most conversations about finance AI in 2026 are about model size, model providers, and which agent does what. Those are the wrong questions. The better place to start first is whether the model has seen enough of the messy edge cases AP teams deal with every day. The second is whether everything around the model is built to operate at enterprise scale on the days when the model gets it wrong. Both matter. The second one is where most of the actual work lives, and it gets the least airtime.
For almost every finance AI on the market right now, the answer to both of those questions is no. That is not a criticism of the models. General-purpose foundation models have read the internet. They have not read your supplier master, your account codes, or the ten thousand judgment calls your AP team made last year about an ambiguous freight charge.
The grounding problem
We use the term Grounded AI to describe an AI system anchored by proprietary, human-validated data and specialized models, with the goal of deterministic accuracy in finance. The grounding is the part that matters. An ungrounded model writes plausible answers. A grounded model writes correct ones.
In invoice processing, the ground truth is not the average case. It is the long tail. Headers and totals are easy. Standard tax codes are easy. The cases that determine whether automation works are the ones where a supplier has changed their invoice format, where a line item is ambiguous, where a tax jurisdiction has updated its rules, or where a discount applies in one region but not another.
Synthetic data cannot fill this gap. The corrections in real-world invoice data are artifacts of human judgment on cases that were ambiguous when they arrived. You cannot generate the ambiguity synthetically without already knowing the answer.
This is why the long tail is a moat. A foundation model trained on the internet has not seen your edge cases. A model trained on a decade of finance-specific corrections has.
The Medius data foundation
Medius has built an eval set of 393 million unique data points: human judgment applied to over a decade of the messiest invoice data in the industry. That is the number that matters.
Each data point is a labeled edge case. A model proposed an answer; a human disagreed and corrected it. Across 393 million corrections, you build something no amount of compute or model scale can substitute for.
That eval set comes from operational scale. Medius runs in production at over 4,000 customers, processes around six million invoices a month, and holds an archive of more than 300 million invoices going back a decade. The corrections are the by-product of that footprint, and the reason the next model gets a sharper answer than the last.
Medius Grounded AI Architecture
Specialized models for deterministic work, LLMs for reasoning, a gate in between.

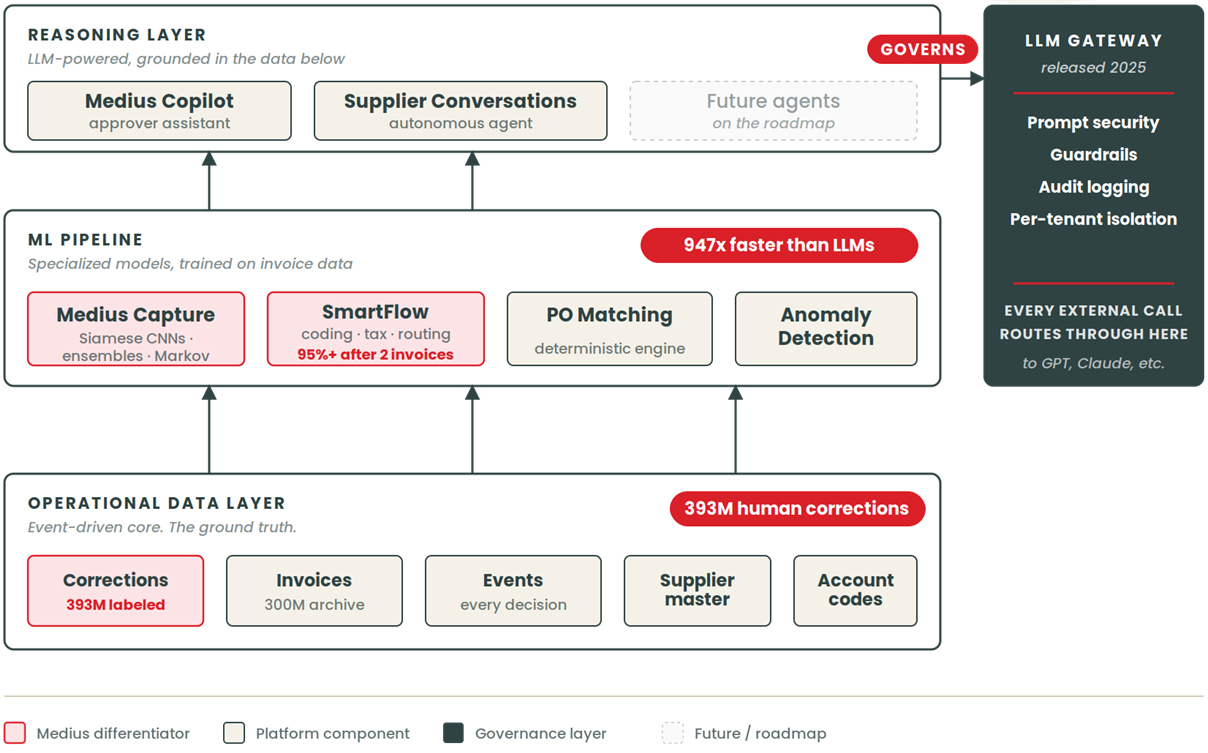
Source: Medius engineering. Stats reflect production deployment as of 2026.
Figure 1. Medius Grounded AI Architecture. Specialized models for deterministic work, LLMs for reasoning, a gate in between.
Underneath the data is an event-driven core. Every correction, exception decision, and edge-case resolution gets captured as a discrete event, not just a state change in a database. That distinction matters for two reasons. First, it makes the dataset rich enough to train on. Second, it makes the platform legible and actionable to agents, which we come back to at the end.
What the model layer doesn't see
An AI that extracts an invoice perfectly is still only at the start of the work. The extracted invoice may need to be matched against a purchase order that may not exist yet. It has to be coded against a chart of accounts that varies by entity, country, and tax jurisdiction. It has to be routed to the right approver under rules that change as people change roles. It has to be checked against contract terms in a different system. And every step has to leave a trail an auditor can reconstruct months or years later.
This is the operational layer. It is what an LLM does not see, and it is where most of the effort in enterprise AP automation actually lives.
In addition to the operational layer, there is infrastructure to be considered. ERP integration is a set of bidirectional, near-real-time connections to systems like SAP, Oracle, and Microsoft Dynamics, each with their own data models. Workflow orchestration is a multi-tenant rules engine running thousands of customer-specific approval policies at scale. Compliance handling means meeting e-invoicing mandates spreading rapidly across Europe and Latin America, with format and reporting requirements that vary by country.
Each of these is a multi-year engineering investment. None of them is a model problem. A startup with a foundation model and a clever prompt can solve the easy 20% of the problem: the extraction. The other 80% is where the platform earns its place, and where finance teams actually need software they can trust.
The layered AI pipeline
The pipeline that sits on top of this data is layered, and the layering is deliberate. Different problems want different kinds of model. We use the right kind for each job.
Medius Capture is a multi-stage ML pipeline that uses Siamese CNNs for layout-aware field extraction, tree-based ensembles for classification and coding decisions, and Markov models for line-item parsing. These are specialized models, trained on invoice data specifically. They run roughly 1000x faster and 25x more cost-effectively than off-the-shelf large language models for the same extraction work.


“Extraction is a deterministic problem. Deterministic problems get solved better and cheaper by purpose-built models. We use LLMs where they actually help, which is reasoning and conversation. We do not use them as a sledgehammer for jobs that have a right answer.”
John Seery, CTO, Medius
SmartFlow is our proprietary CNN. It auto-fills coding, tax codes, and approver values with 95%+ accuracy and with 95%+ precision after learning from just two invoices from a new supplier. Two invoices. That is what trained-on-the-right-data looks like in practice.
Ardent Partners' 2025 AP Metrics That Matter report puts industry best-in-class at 49.2% touchless on PO invoices. Medius customers average 68.9%. Our average runs nearly 20 points above the industry’s best. Our top performers reach 96.3%. The gap is the architecture.
AI-driven straight-through processing
PO invoices - Touchless processing rate

1 Ardent Partners' Accounts Payable Metrics that Matter in 2025
2 Medius AP Automation Benchmark Report 2025
Non-PO touchless: 99.5% (Medius top performers; no comparable industry benchmark).
Figure 2. PO invoice touchless processing. Medius vs industry baselines (Ardent Partners, 2025; Medius AP Automation Benchmark, 2025).
Where LLMs actually belong
LLMs solve problems traditional AI cannot: chasing down the long tail of difficult exceptions, replying in natural language to supplier inquiries, reasoning across context. Medius is excited about LLMs because we can put them to work where they earn their place, on top of the grounded data and inside the operational platform. Two examples already in production today:
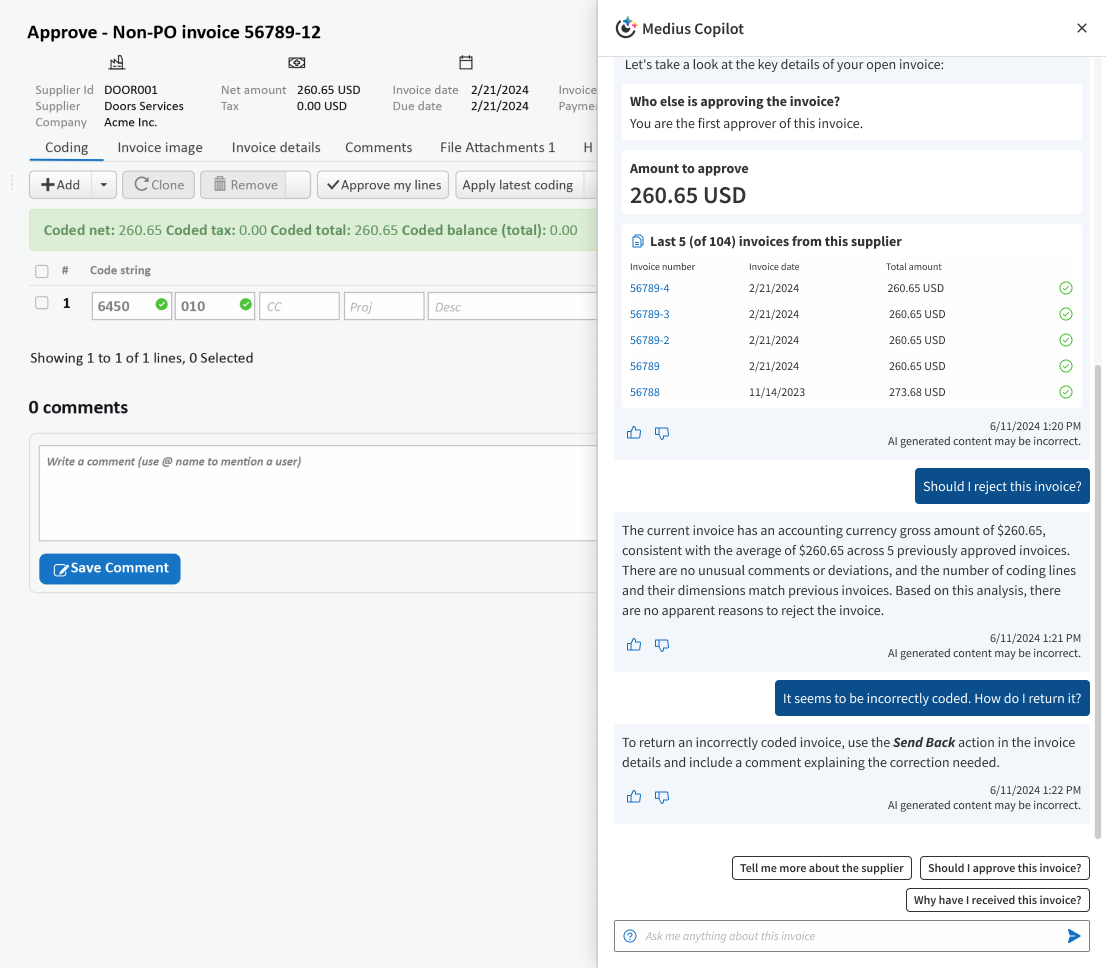
Medius Copilot is an AI assistant in production at over 400 customers and 3,300+ users. It provides contextual reasoning and support for approver decisions: surfacing relevant history, flagging anomalies and summarizing context. The reasoning is what an LLM is good at. What it is reasoning over is grounded data: actual invoices, actual coding history, actual approval patterns from the same customer's environment.


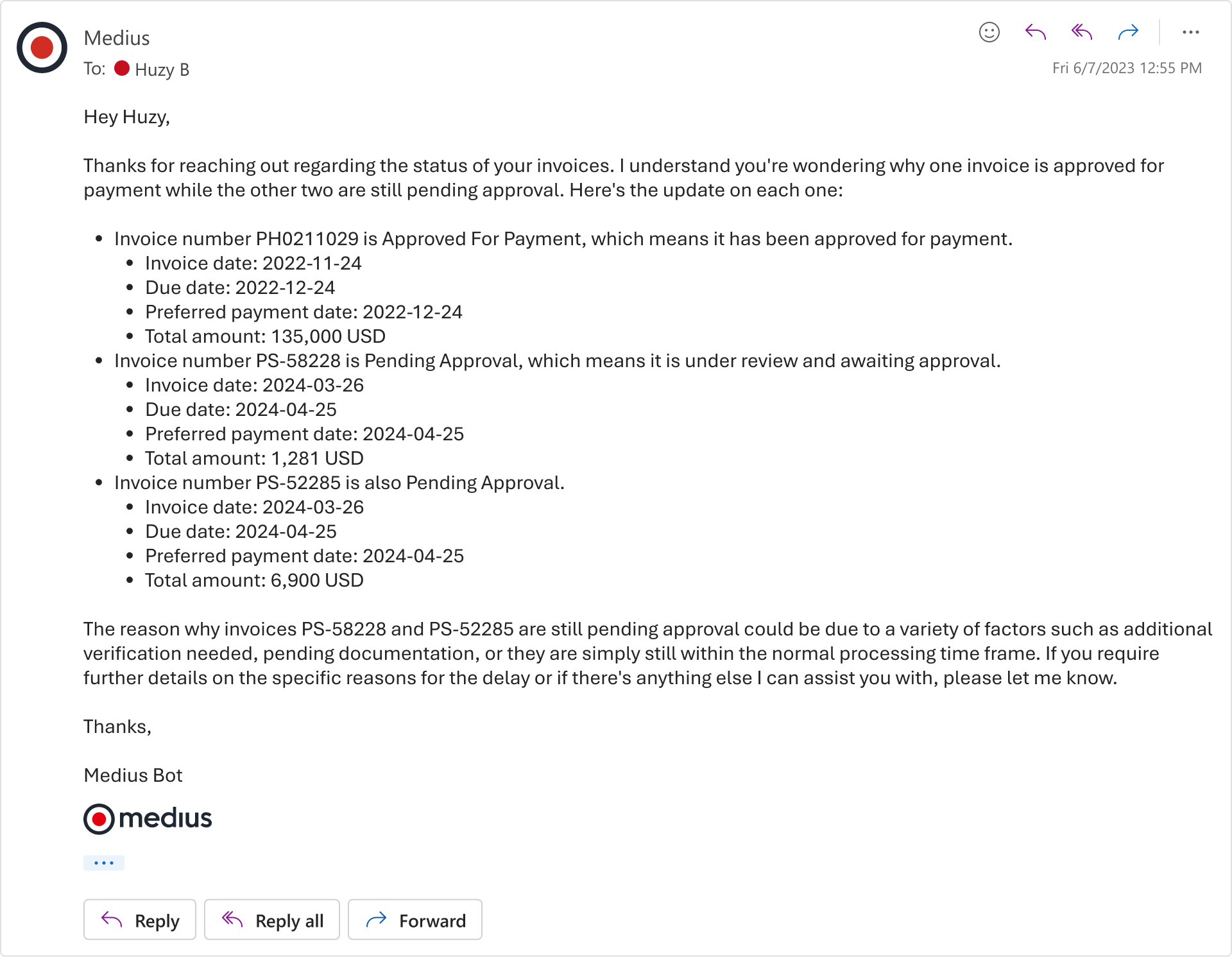
Supplier Conversations is an autonomous agent that classifies and responds to vendor inquiries within defined guardrails. It handles around 13,000 supplier emails a month across 160 customers, with around 94% reduction in inbox time. AP teams report dropping from roughly 8 hours a week on supplier email to 30 minutes. Again, the LLM does the language part. The grounding tells it what is true about the supplier's situation.
The architecture compounds at cycle time too. Industry best-in-class is 3.1 days to process an invoice. Medius top performers run at 1.4 days. Put the right model at each layer, and the time compresses.
AI-accelerated cycle time
PO invoices - Total invoice processing time

1 Ardent Partners' Accounts Payable Metrics that Matter in 2025
2 Medius AP Automation Benchmark Report 2025
Non-PO touchless: 99.5% (Medius top performers; no comparable industry benchmark).
Figure 3. PO invoice cycle time. Medius vs industry baselines (Ardent Partners, 2025; Medius AP Automation Benchmark, 2025).
Both Medius Copilot and Medius Supplier Conversations run through the Medius LLM Gateway (our governance layer for foundation-model calls), released in 2025. It enforces prompt security, guardrails, and full audit logging on every external model call. Every AI decision the system makes is logged and traceable. The Gateway is what makes the architectural principle workable in regulated environments.
So can a startup replicate this?
A startup with the latest foundation model can replicate the easy parts of AP automation quickly. They can extract invoices, build a chat interface, and demo something impressive. That is good news for the industry.
They cannot replicate ten years of operational data and 393 million human corrections. They cannot replicate the integration depth, the workflow engine, the compliance coverage, or the audit infrastructure that enterprise AP requires, much of it documented at trust.medius.com. They cannot replicate the production deployment of layered specialized models alongside reasoning agents inside a governed gateway. Those things take time, and they take customers, and they take the kind of engineering investment that does not show up in a demo.
That is the data moat. It is the foundation that makes the next thing possible: agents.
There is a lot of agent talk in finance software right now. Most of it is unanchored. An agent that acts on invoice data without grounding takes the wrong action. An agent that calls an LLM without governance cannot pass an audit. An agent without an event-driven platform to act on can read state but cannot do work.
Medius has put each of those preconditions in place.
That is what makes the agent roadmap a credible extension of the work, not a leap into something new. We come back to that in the next piece in this series.





